全国高分辨率土地利用数据服务 土地利用数据服务 土地覆盖数据服务 坡度数据服务 土壤侵蚀数据服务 全国各省市DEM数据服务 耕地资源空间分布数据服务 草地资源空间分布数据服务 林地资源空间分布数据服务 水域资源空间分布数据服务 建设用地空间分布数据服务 地形、地貌、土壤数据服务 分坡度耕地数据服务 全国大宗农作物种植范围空间分布数据服务
多种卫星遥感数据反演植被覆盖度数据服务 地表反照率数据服务 比辐射率数据服务 地表温度数据服务 地表蒸腾与蒸散数据服务 归一化植被指数数据服务 叶面积指数数据服务 净初级生产力数据服务 净生态系统生产力数据服务 生态系统总初级生产力数据服务 生态系统类型分布数据服务 土壤类型质地养分数据服务 生态系统空间分布数据服务 增强型植被指数数据服务
多年平均气温空间分布数据服务 多年平均降水量空间分布数据服务 湿润指数数据服务 大于0℃积温空间分布数据服务 光合有效辐射分量数据服务 显热/潜热信息数据服务 波文比信息数据服务 地表净辐射通量数据服务 光合有效辐射数据服务 温度带分区数据服务 山区小气候因子精细数据服务
全国夜间灯光指数数据服务 全国GDP公里格网数据服务 全国建筑物总面积公里格网数据服务 全国人口密度数据服务 全国县级医院分布数据服务 人口调查空间分布数据服务 收入统计空间分布数据服务 矿山面积统计及分布数据服务 载畜量及空间分布数据服务 农作物种植面积统计数据服务 农田分类面积统计数据服务 农作物长势遥感监测数据服务 医疗资源统计数据服务 教育资源统计数据服务 行政辖区信息数据服务
Landsat 8 高分二号 高分一号 SPOT-6卫星影像 法国Pleiades高分卫星 资源三号卫星 风云3号 中巴资源卫星 NOAA/AVHRR MODIS Landsat TM 环境小卫星 Landsat MSS 天绘一号卫星影像





GoogleMap,VirtualEarth,YahooMap等,目前所有的WebGIS都使用了缓存机制以提高地图访问速度。原理都是将地图设定为多个比例尺,对于每个比例尺提前将地图分成若干小图片,存在服务器上,客户端访问时直接获取需要的小图片拼接成地图,而不是由服务器动态创建出一幅图片来送到客户端,极大程度的提高了反问速度。好比外面卖菠萝,和自己买一整个回家吃不同,提前把一个菠萝等分成四份(js可能会分成6份),你只需买一份来吃,体积小,方便吃,而不是对着整个菠萝咬下去,弄一脸菠萝汁。
本文中来详细了解一下ArcGIS Server目前为地图服务建立缓存(切图)的原理。先来了解一个概念:
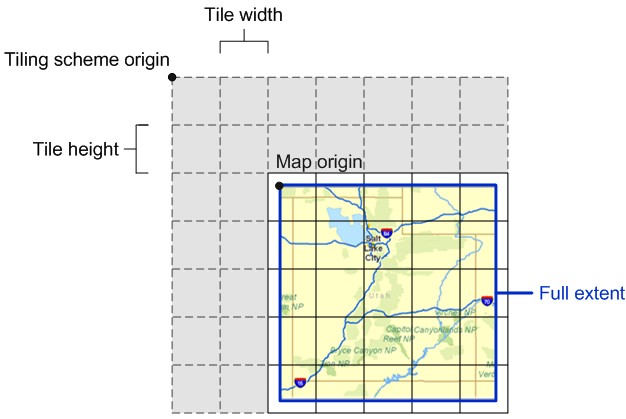
Tiling Scheme:创建地图缓存时使用的一系列参数的总称。包括比例尺级别,图片格式,图片大小等等。
TilingScheme Origin:是tiling schemegrid的左上角。默认情况下就是由mxd文档使用的坐标系的原点。而切图的范围通常是mxd文档中full extent的范围,即从 fullextent的左上角(map origin)到右下角。注意区分map origin与tiling scheme origin。
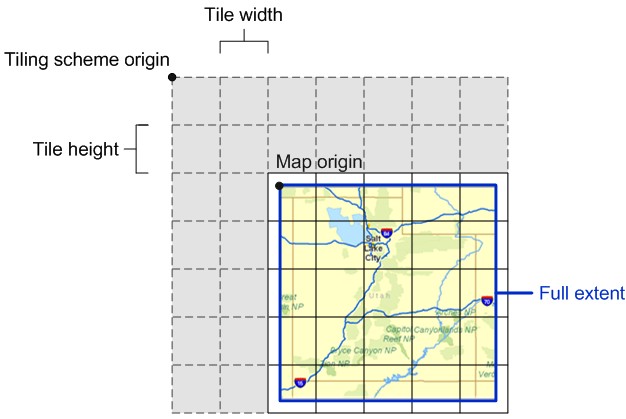
对于不同的地图服务(mxd文档),如果使用相同的坐标系,那么就有相同的tiling scheme origin,即使他们的fullextent不同(map origin不同),也能处于同一参考系中。如果full extent相同,则可以轻松地叠加在一起,这也是tilingscheme origin设计的初衷。默认情况下,切图的范围是mxd文档的full extent。如果手工设置了tiling schemeorigin,那么切图的范围只能是地图范围中tiling scheme origin右下角的部分:如果tiling schemeorigin在map origin的左上角,那么切图范围还是full extent;如果tiling schemeorigin落在地图中,那么切图的范围就是从tiling scheme origin到fullextent的右下角。这也就是为什么建议通过设置特定的矩形范围(92中)或直接使用featureclass(93中)来改变切图范围,而不是利用tiling scheme origin来限制切图范围的原因。
那么地图到底是怎么切出来的?切多少块呢?通过一个例子深入浅出吧。一个中国地图,采用了自定义的坐标系:
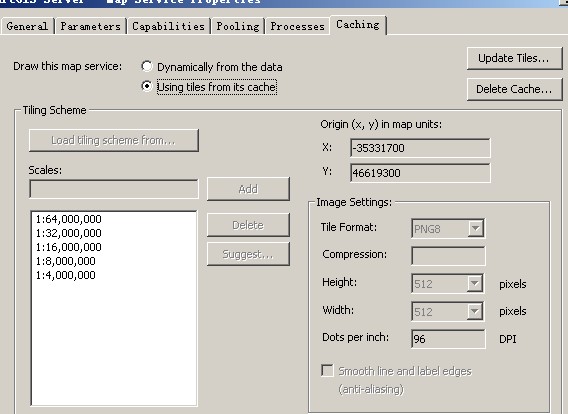
切图时设置如下:
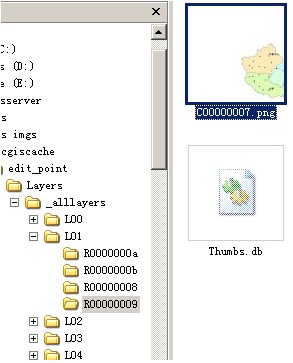
看看切图完成后的文件夹结构:
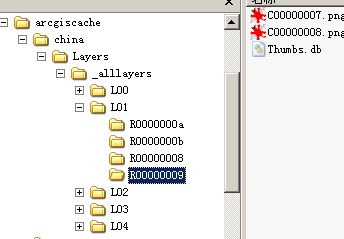
在缓存目录中,首先是地图服务命名的文件夹china;之后是切图的DataFrame命名的文件夹Layers;由于采用的是fused方式,下来就是_alllayers,如果是multi-layer切图,那么就是每个图层的序号文件夹;下来就是切图设置的多个比例尺级别(Level ofDetail,LOD),从小到大,对应前面设置的5个比例尺;一个比例尺文件夹下,是切图的“行”文件夹,命名规则是R加上8位行号(16进制),不足补0。比如图中的R0000000a,表示此比例尺中第10行(16进制中的a);每行文件夹下就是该行的所有tile文件了,命名规则是C加上8位列号(16进制),不足补0。为什么这个比例尺下(L01)中只有8,9,10,11行呢?前面说过切图的范围是fullextent,说明在该比例尺下,从tiling schemeorigin算起,中国地图的范围只占到了这几行,其余没有,不切。同理,对于上面的第九行文件夹中,只有7,8两列,其余的没有,不切。
再打开和_alllayers文件夹同级的conf.xml看看吧,里面保存了整个tiling scheme参数。
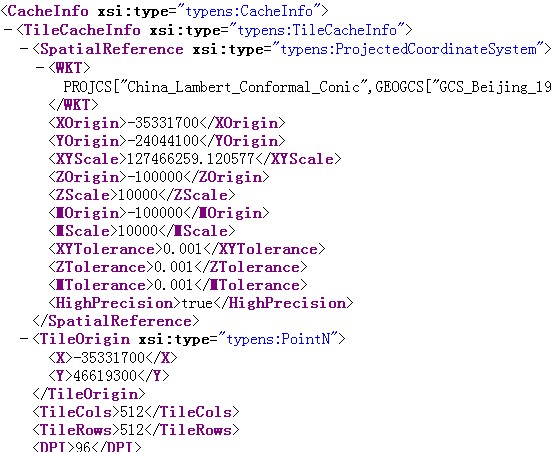
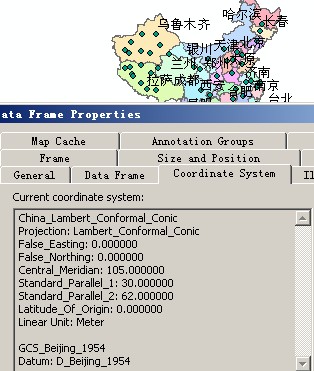
可以看出地图服务使用的坐标系信息,tile图片的DPI(96),每个tile的长度和宽度(512),以及tiling scheme origin。
现在来计算某个比例尺中,地图上一个点所在的tile图片的行列号了。比如计算L01中,乌鲁木齐市所在tile的行列号。需要收集三个信息:
1、获得乌市的地理坐标:在本地图中是x=-1341070,y=5343697;
2、获得tiling scheme:x=-35331700,y=46619300;
3、获得当前比例尺的resolution,即一个像素所占的地图单位长度:在L01比例尺上是8466.68360003387。
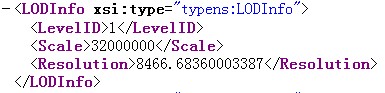
乌市所在的行号:(35331700-1341070)/(8466.6836*512)=7.84=8
乌市所在的列号:(46619300-5343697)/(8466.6836*512)=9.52=10
所以乌鲁木齐在切图的第二个比例尺中,处于第10行,第8列的tile。