全国高分辨率土地利用数据服务 土地利用数据服务 土地覆盖数据服务 坡度数据服务 土壤侵蚀数据服务 全国各省市DEM数据服务 耕地资源空间分布数据服务 草地资源空间分布数据服务 林地资源空间分布数据服务 水域资源空间分布数据服务 建设用地空间分布数据服务 地形、地貌、土壤数据服务 分坡度耕地数据服务 全国大宗农作物种植范围空间分布数据服务
多种卫星遥感数据反演植被覆盖度数据服务 地表反照率数据服务 比辐射率数据服务 地表温度数据服务 地表蒸腾与蒸散数据服务 归一化植被指数数据服务 叶面积指数数据服务 净初级生产力数据服务 净生态系统生产力数据服务 生态系统总初级生产力数据服务 生态系统类型分布数据服务 土壤类型质地养分数据服务 生态系统空间分布数据服务 增强型植被指数数据服务
多年平均气温空间分布数据服务 多年平均降水量空间分布数据服务 湿润指数数据服务 大于0℃积温空间分布数据服务 光合有效辐射分量数据服务 显热/潜热信息数据服务 波文比信息数据服务 地表净辐射通量数据服务 光合有效辐射数据服务 温度带分区数据服务 山区小气候因子精细数据服务
全国夜间灯光指数数据服务 全国GDP公里格网数据服务 全国建筑物总面积公里格网数据服务 全国人口密度数据服务 全国县级医院分布数据服务 人口调查空间分布数据服务 收入统计空间分布数据服务 矿山面积统计及分布数据服务 载畜量及空间分布数据服务 农作物种植面积统计数据服务 农田分类面积统计数据服务 农作物长势遥感监测数据服务 医疗资源统计数据服务 教育资源统计数据服务 行政辖区信息数据服务
Landsat 8 高分二号 高分一号 SPOT-6卫星影像 法国Pleiades高分卫星 资源三号卫星 风云3号 中巴资源卫星 NOAA/AVHRR MODIS Landsat TM 环境小卫星 Landsat MSS 天绘一号卫星影像






疑惑篇中简单介绍了基于ArcSDE的影像数据管理的基本方法、策略及其缺陷。那么要想基于ArcSDE的Raster Catalog实现对影像数据的任意范围查询,并且在跨图幅的情况下做到无缝拼接该怎么实现呢?
疑惑篇中简单介绍了基于ArcSDE的影像数据管理的基本方法、策略及其缺陷。那么要想基于ArcSDE的Raster Catalog实现对影像数据的任意范围查询,并且在跨图幅的情况下做到无缝拼接该怎么实现呢?
我是这样做的。
首先说说逻辑上的思路。
问题的输入和输出都是很明确的。
输入:BBox, w
说明一下,BBox是Bounding Box的缩写,是以地理坐标表示的查询范围,由left, right, top和bottom四个参数组成;w为视口的大小,即最终显示在Web上(我说过的哦,这个影像数据源包装器是一个WebGIS项目服务器端的一部分)给用户看的地图窗口的大小,由width和height两个参数组成。
输出:与查询范围精确匹配的一幅w大小的jpeg图像文件
再说明一下,jpeg图像是经过有损压缩的,数据量比较小,我程序中每次得到的图像文件数据量一般在50~100K左右,在Internet上传输是可以接受的。这种图像不带坐标信息,也无法进行二次处理,就是纯粹的一张图片,很纯的那种。这不太符合OGC的WCS规范,因为我现在只能提供jpeg图像;但却有点像WMS,如果把接口改改的话就算勉强符合。
那么根据ArcSDE中影像数据的管理和存储方式,从逻辑上我按照以下步骤完成功能:
第一步:根据BBox与w计算显示比例尺s;
第二步:根据s计算提取数据所在的金字塔级别l;
第三步:通过一次散列,求出与BBox相交的图幅序列ImageList(I1, I2, I3…);
第四步:将BBox分解到ImageList中的每一个图幅元素上成为子查询序列subBBox(sb1, sb2, sb3…);
第五步:在l级金字塔上,通过第二次散列,在Ii上求出与sbi相交的图块序列TileListi(B1, B2, B3…);
第六步:提取第三步得到的全部图块的数据;
第七步:将第四步得到的数据还原成位图文件
嗯,总体上就是这个样子。下面逐步细说。
第一、二步挺简单不用解释,第三步开始就有问题了。
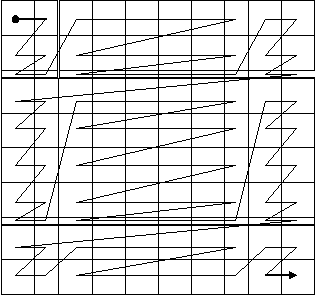
在疑惑篇中我说了,SDE认为Raster Catalog就是一“相册”,其中存储的影像是没有什么关系的,更不会为它们建立什么索引结构。这样要想实现第三步中的散列就要先为Raster Catalog中的图幅建立索引表,这个表我建在了影像数据所在的表空间里,名字就叫IMAGEINDEX,里面为所有图幅按照它们之间的拓扑关系建立了格网索引——每个图幅一个行号、一个列号。但这时就又有问题了,基础数据一共460个图幅,全拼起来并不是一个大长方形,而是基本与目标区域边界吻合的锯齿形。那么若建立格网索引就必然会有一些空的地方,就是说会有一些格网号并没有实际的图幅与之对应。那么对于这些空的地方,我是将它们也写入索引表,但标识其目标为0呢还是直接跳过它们不管呢?我选择了前者。这样,一个如下面示意图所示的格网索引就建起来了,第一次散列的问题也就可以解决了。而第五步中的第二次散列由于SDE对每个图幅中的图块是做了格网索引的(疑惑篇中有介绍),所以易于实现。

下面是最关键的第三到第五步,在这三步中,我要完成图幅的去零,以支持跨幅查询时的无缝拼接。因为我可以通过SDE API得到每个图幅原来的大小,即未补零时的大小,还可以得到图块的大小,通过它们就可以算出图幅边缘补零部分的宽度和高度,当查询涉及到那些带有零元的图块时,我就能知道其中有效信息部分的大小,进而只读取它们,跳过零元。但这带来一个小问题,就是图块的大小出现了不均匀。为此,我采用了一种比较笨的办法,就是让ImageList中的每个图幅Ii都自己记录自己的TileListi中每个图块的大小。这样在第六步提取数据和第七步恢复图像的时候就可以按照每个图块的实际大小来读写,而那些补的零就都可以去死了。这就是我去零的基本思路。
提取每个图块数据时,外层循环对ImageList的遍历顺序是Z序的,而内层循环在每个图幅内部对TileList的访问顺序也是Z序的。与之对应的,在恢复图像的时候,在每个图块内部绘制像素的顺序、在每个图幅内绘制图块的顺序、绘制图幅的顺序也都是Z序的。如下图所示:
最后一步得到位图还没完,需要再稍做加工,因为它的地理范围比BBox要大(因为提取数据的最小单位是图块而不是像素,这个应该好理解吧),所以要将它中间BBox对应的那一部分切出来。这还没完,切出来的部分可能不是w大小(这是因为金字塔索引是离散的,按比例尺拿数据只能就近取金字塔中的某一级),但不会差很远,所以还要稍微拉伸才行。这样两步加工之后得到的才是最终产品。
以上就是我整个思路的要点概况,其中关键的就在去零实现无缝拼接,不知道说清楚了没有。其实办法也挺初级的,疑惑篇的评论中bluntsword一下就给出解决思路了。本人比较笨,唉~~
下面再说说具体实现吧。事先说明一下,我的OOA/D经验相当匮乏,具体解决方案给出之后大家可能会觉得十分龌龊而不堪如目,其中可能会有不计其数的违背OO原则的地方,但请大家相信这也绝非我本意。诸位如果实在看不下去想骂两句的话就不用忍了。如果有一天我能看到某介绍设计方案的文献上有我的设计——作为反面教材,那我也无怨无悔。不过虽然它很丑,但它在我们整个WebGIS系统中还算是比较稳定的一块。
SDE C-API是C写的(废话!),其中使用了少量C++的特性,不支持我相对比较熟悉的.net,所以我选择了VC6来实现。
这个影像数据包装器只负责从影像数据源中抽取数据,形成图片,并传回给GIS服务器,所以其实它连界面都不需要,但我建了个对话框应用,上面摆一个Edit,用于输出运行时的一些状态信息。
为实现功能,我建了一个CMyRaster类,它的内部完成了我想要的全部事情(这是不是一个典型的“全能类”啊,好怕怕~~)。其结构如下:(由于不能贴C++代码,所以这里暂且用C#格式的,下同)
class CMyRaster
{
public:
static WCHAR* ToWChar(char * str); // 在GDI+中,有关字符的参数类型全部都是WCHAR类型,该函数是将传统字符串进行转换
static int DisconnectSDE(SE_CONNECTION *connection); // 断开与SDE的连接
static int ConnectSDE(char *SDE_servername, char *SDE_service, char *SDE_instance, char *SDE_user, char *SDE_password, SE_CONNECTION *connection); // 连接SDE
// 这里应该提供一个ConnectSDE的重载版本用于连接SQLServer服务器
int GetRaster(const SE_CONNECTION connection, const _ConnectionPtr ADOConn, double left, double right, double top, double bottom, long userScale, CString filename); // 提取影像数据并生成图片的核心方法
CMyRaster();
virtual ~CMyRaster();
private:
int m_QueryRasterRight; // 与查询范围相交的图幅序列的格网索引范围
int m_QueryRasterLeft;
int m_QueryRasterTop;
int m_QueryRasterBottom;
RASTER_METADATA *m_RastersMetadata; // 图幅元数据数组,核心变量
char strTableName[SE_QUALIFIED_TABLE_NAME]; // Raster Catalog的表名
char strColName[SE_MAX_COLUMN_LEN]; // 数据的列名,一般就是"IMAGE"
int m_QueryPyramidLevel; // 查询所在的金字塔级别
SE_INTERPOLATION_TYPE m_Interpolation; // 插值的方法
long *m_ScaleByLevel; // 金字塔该级别上的比例尺
long m_NumOfBands; // 波段数
long m_PyramidHeight; // 金字塔高度
IMAGE_EXTENT m_DefaultTileSize; // tile大小的预设值
SE_ENVELOPE m_WholeExtent; // 最大的全图范围
int m_UserMapWidth; // 用户地图区的宽度
int m_UserMapHeight; // 用户地图区的高度
int Get_RasterMetadata_by_BBox(const SE_CONNECTION connection, const _ConnectionPtr ADOConn, double left, double right, double top, double bottom, long userScale); // 获取SDE中raster图层的元数据
int Get_RasterData_from_SDE(const SE_CONNECTION connection, const _ConnectionPtr ADOConn); // 从数据源中提取影像数据
int Write_to_BMP_file(double left, double right, double top, double bottom, CString filename); // 将影像数据恢复成位图文件
LONG GetScale(LFLOAT ras_xLength, LONG rasWidth, BOOL isBigFont); // 计算比例尺
int Get_RasterMetadata_by_GridIndex(int rasrownbr, int rascolnbr, int *rasIndex); // 根据格网索引取图幅
int GetImageCLSID(const WCHAR* format, CLSID* pCLSID); // 得到格式为format的图像文件的编码值,访问该格式图像的COM组件的GUID值保存在pCLSID中
int Get_PyramidLevel_by_scale(long userScale, int *pyramidLevel); // 根据比例尺获取金字塔索引的级别
int Get_Result_extent(SE_ENVELOPE *resultExtent); // 获取结果位图的地理范围
};
从CMyRaster类的结构可以看出我将围绕
RASTER_METADATA *m_RastersMetadata;
这个动态数组来做文章。RASTER_METADATA是一个定义在CMyRaster外面的结构体,细节如下:
typedef struct raster_metadata
{
// 下面是每个raster对应的唯一属性
int m_RasterID; // Raster_ID
int m_RasterRowNum; // 图幅格网索引行标号
int m_RasterColNum; // 图幅格网索引列标号
int m_QueryTileLeft; // 查询范围对应的tile最左一列的列号
int m_QueryTileRight; // 查询范围对应的tile最右一列的列号
int m_QueryTileTop; // 查询范围对应的tile最上一行的行号
int m_QueryTileBottom; // 查询范围对应的tile最下一行的行号
SE_ENVELOPE m_RasterExtent; // 全图的地理坐标范围
IMAGE_EXTENT m_ImageSize; // 全图的像素范围
IMAGE_EXTENT m_QueryImageSize; // 与查询范围相交的像素范围
IMAGE_EXTENT *m_QueryTilesSize; // 查询范围对应的每个tile的大小(不带零)
// 下面是每个raster中每级金字塔对应的属性,均为数组,其大小在运行时才能确定
IMAGE_EXTENT *m_ImageSizeByLevel; // 金字塔该级别上像素范围
IMAGE_EXTENT *m_ZerosSizeByLevel; // 金字塔该级别上补零部分的宽与高
SE_ENVELOPE *m_RasterExtentByLevel; // 金字塔该级别上的地理坐标范围
int *m_TotalTileColByLevel; // 金字塔该级别上以tile为单位的列数
int *m_TotalTileRowByLevel; // 金字塔该级别上以tile为单位的行数
}RASTER_METADATA;
公有方法GetRaster(…)是完成功能的“主”方法,其中就这么三句话:
// 通过查询范围获取与查询范围相交的全部图幅的元数据
int ret = Get_RasterMetadata_by_BBox(connection, ADOConn, left, right, top, bottom, scale);
if (ret != SE_SUCCESS)
return -1;
// 获取上面求出的图幅序列的像素数据
ret = Get_RasterData_from_SDE(connection, ADOConn);
if (ret != SE_SUCCESS)
return -1;
// 将存储在临时文件中的像素数据还原成位图
ret = Write_to_BMP_file(left, right, top, bottom, filename);
if (ret != SE_SUCCESS)
return -1;
逻辑设计中的第一、二步都有与其对应的函数实现。第三至第五步则化为GetRaster(…)中的
// 通过查询范围获取与查询范围相交的全部图幅的元数据
int ret = Get_RasterMetadata_by_BBox(connection, ADOConn, left, right, top, bottom, scale);
if (ret != SE_SUCCESS)
return -1;
Get_RasterMetadata_by_BBox函数用于填充m_RastersMetadata数组,以供后面使用。
第六步提取数据由
// 获取上面求出的图幅序列的像素数据
ret = Get_RasterData_from_SDE(connection, ADOConn);
if (ret != SE_SUCCESS)
return -1;
实现,其依据m_RastersMetadata数组中的数据,通过SDE API提供的读取图块的API来按块提取数据。取出的数据是以字节流的形式存入磁盘临时文件,因为公有R、G、B三个波段的数据,所以相应的就有三个临时文件。
第七步重新绘制图像则由
// 将存储在临时文件中的像素数据还原成位图
ret = Write_to_BMP_file(left, right, top, bottom, filename);
if (ret != SE_SUCCESS)
return -1;
完成,绘制图像我使用的是GDI+,感觉就是两个字:简单,好用。
在这个影像包装器子系统中,最耗时的环节并不是提取数据和还原图像,而是连接SDE。也不知是什么原因,当后台数据库是Oracle的时候,这个连接动作总是如此如此如~~~此的慢。第一次连接一般要一分钟左右,以后每次也要几十秒。如果每次查询都要连接SDE,那后果简直不可想象(我曾经做过的一个基于MO的矢量数据发布系统就是每次都要连接,以至于做一次地图放大或者平移都要等一分多钟,唉,实在对不起用户)。所以我把连接SDE的动作放在了InitDialog中,并在整个程序生命期内保持,直到退出时才断开。
实现方面也就是这样了。


