全国高分辨率土地利用数据服务 土地利用数据服务 土地覆盖数据服务 坡度数据服务 土壤侵蚀数据服务 全国各省市DEM数据服务 耕地资源空间分布数据服务 草地资源空间分布数据服务 林地资源空间分布数据服务 水域资源空间分布数据服务 建设用地空间分布数据服务 地形、地貌、土壤数据服务 分坡度耕地数据服务 全国大宗农作物种植范围空间分布数据服务
多种卫星遥感数据反演植被覆盖度数据服务 地表反照率数据服务 比辐射率数据服务 地表温度数据服务 地表蒸腾与蒸散数据服务 归一化植被指数数据服务 叶面积指数数据服务 净初级生产力数据服务 净生态系统生产力数据服务 生态系统总初级生产力数据服务 生态系统类型分布数据服务 土壤类型质地养分数据服务 生态系统空间分布数据服务 增强型植被指数数据服务
多年平均气温空间分布数据服务 多年平均降水量空间分布数据服务 湿润指数数据服务 大于0℃积温空间分布数据服务 光合有效辐射分量数据服务 显热/潜热信息数据服务 波文比信息数据服务 地表净辐射通量数据服务 光合有效辐射数据服务 温度带分区数据服务 山区小气候因子精细数据服务
全国夜间灯光指数数据服务 全国GDP公里格网数据服务 全国建筑物总面积公里格网数据服务 全国人口密度数据服务 全国县级医院分布数据服务 人口调查空间分布数据服务 收入统计空间分布数据服务 矿山面积统计及分布数据服务 载畜量及空间分布数据服务 农作物种植面积统计数据服务 农田分类面积统计数据服务 农作物长势遥感监测数据服务 医疗资源统计数据服务 教育资源统计数据服务 行政辖区信息数据服务
Landsat 8 高分二号 高分一号 SPOT-6卫星影像 法国Pleiades高分卫星 资源三号卫星 风云3号 中巴资源卫星 NOAA/AVHRR MODIS Landsat TM 环境小卫星 Landsat MSS 天绘一号卫星影像





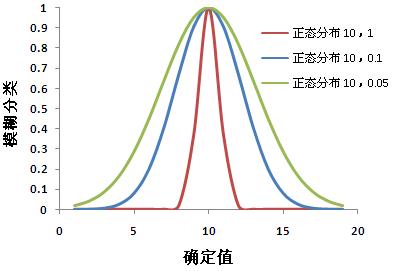
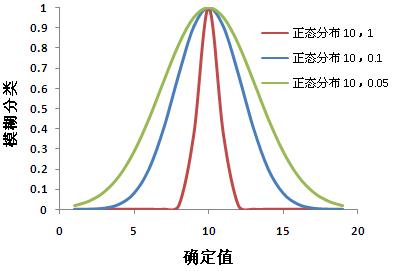
根据指定的模糊化算法,将输入栅格转换为 0 到 1 数值范围以指示其对某一集合的隶属度。
值 1 表示完全隶属于模糊集,而当值降为 0 时,则表示不是模糊集的成员。
· 此工具无法对分类数据进行度量。要将分类数据用于模糊叠加分析,需要执行预处理操作。您可以创建一个模型或运行下列地理处理工具。首先,使用重分类工具获得一个新的值域范围(例如,1 到 100)。然后,将重分类结果除以某个因子(例如 100),以便将输出值归一化为介于 0.0 和 1.0 之间的值。
· 散度 (Spread) 可确定模糊隶属度从 1 下降到 0 的速度。其值越大,中点周围的模糊化就越陡。换言之,随着散度 (spread) 的减小,模糊隶属度接近 0 的速度也将随之降低。选择合适的散度 (spread) 值是一个主观过程,它取决于明确值的数值范围。对于高斯函数和近邻 (Near) 函数,使用默认值 0.1 是一个很好的出发点。通常,值分别在 [0.01–1] 或 [0.001-1] 的区间内变化。对于小值 (Small) 函数和大值 (Large) 函数,使用默认值 5 是一个很好的出发点,通常,值在 1 和 10 之间变化。
· 您有时可能会遇到没有任何一个输入值可以保证 100% 属于指定集合的情况。也就是说,没有任何一个输入值的模糊隶属度为 1。这种情况下,可能需要重新调整模糊隶属度的大小以反映出新的范围。例如,如果输入值的最大隶属度为 0.75,则可以通过将每个模糊隶属度乘以 0.75 来获得新的范围。
· 执行的模糊限制语是 Very 和 Somewhat。Very 也称为浓缩,被定义为模糊隶属函数的平方。Somewhat 也称为膨胀或 More or Less,是模糊隶属函数的平方根。very 和 somewhat 模糊限制语可分别减小和增大模糊隶属函数。
· 小值 (Small) 和大值 (Large) 隶属函数不接受负值。
· 对于线性 (Linear) 隶属函数,输入栅格必须为序列化的数据。最小值可以小于最大值以创建正斜率的函数,也可以大于最大值以创建负斜率的函数来适应这种变换。
如果最小值小于最大值,则使用正斜率函数进行变换;如果最小值大于最大值,则会使用负斜率函数。
FuzzyMembership (in_raster, {fuzzy_function}, {hedge})
|
参数 |
说明 |
数据类型 |
|
in_raster |
值域从 0 到 1 的输入栅格。 |
Raster Layer |
|
fuzzy_function (可选) |
指定用于模糊化输入栅格的算法。 模糊分类用于指定隶属度的类型。 可用的隶属度类型为: · 模糊高斯 (FuzzyGaussian)、模糊大值 (FuzzyLarge)、模糊线性 (FuzzyLinear)、模糊 MS 大值 (FuzzyMSLarge)、模糊 MS 小值 (FuzzyMSSmall)、模糊近邻 (FuzzyNear) 和模糊小值 (FuzzySmall)。 隶属度各类别的形式如下: · FuzzyGaussian({midpoint},{spread}) · FuzzyLarge({midpoint},{spread}) · FuzzyLinear({min},{max}) · FuzzyMSLarge({mean_multiplier},{std_multiplier}) · FuzzyMSSmall({mean_multiplier},{std_multiplier}) · FuzzyNear({midpoint},{spread}) · FuzzySmall({midpoint},{spread}) |
Fuzzy function |
|
hedge (可选) |
定义模糊限制语将增大或减小可修改模糊集含义的模糊分类值。模糊限制语在帮助控制条件或重要属性时非常有用。 · NONE —不应用模糊限制语。这是默认设置。 · SOMEWHAT —也称为膨胀,被定义为模糊分类函数的平方根。该模糊限制语可增大模糊分类函数。 · VERY —也称为浓缩,被定义为模糊隶属函数的平方。该模糊限制语可减小模糊隶属函数。 |
String |
|
名称 |
说明 |
数据类型 |
|
out_raster |
输出为浮点型栅格,取值范围是 0 到 1。 |
Raster |
该示例通过高斯函数创建了一个模糊隶属度栅格,其中,距离中点 (1,200 ft) 较近的高程值的隶属度值较大。
import arcpy
from arcpy.sa import *
from arcpy import env
env.workspace = "c:/sapyexamples/data"
outFzyMember = FuzzyMembership("elevation", FuzzyGaussian(1200, 0.06))
outFzyMember.save("c:/sapyexamples/fzymemb")
该示例通过高斯函数和值为 0.4 的散度创建了一个模糊隶属度栅格,其中,距离中点 (1,000 ft) 较近的高程值的隶属度较大。
# Name: FuzzyMembership_Ex_02.py
# Description: Scales input raster data into values ranging from zero to one
# indicating the strength of a membership in a set.
# Requirements: Spatial Analyst Extension
# Import system modules
import arcpy
from arcpy import env
from arcpy.sa import *
# Set environment settings
env.workspace = "C:/sapyexamples/data"
# Set local variables
inRaster = "elevation"
# Create the FuzzyGaussian algorithm object
midpoint = 1000
spread = 0.4
myFuzzyAlgorithm = FuzzyGaussian(midpoint, spread)
# Check out the ArcGIS Spatial Analyst extension license
arcpy.CheckOutExtension("Spatial")
# Execute FuzzyMembership
outFuzzyMember = FuzzyMembership(inRaster, myFuzzyAlgorithm)
# Save the output
outFuzzyMember.save("c:/sapyexamples/fzymemb2")


