全国高分辨率土地利用数据服务 土地利用数据服务 土地覆盖数据服务 坡度数据服务 土壤侵蚀数据服务 全国各省市DEM数据服务 耕地资源空间分布数据服务 草地资源空间分布数据服务 林地资源空间分布数据服务 水域资源空间分布数据服务 建设用地空间分布数据服务 地形、地貌、土壤数据服务 分坡度耕地数据服务 全国大宗农作物种植范围空间分布数据服务
多种卫星遥感数据反演植被覆盖度数据服务 地表反照率数据服务 比辐射率数据服务 地表温度数据服务 地表蒸腾与蒸散数据服务 归一化植被指数数据服务 叶面积指数数据服务 净初级生产力数据服务 净生态系统生产力数据服务 生态系统总初级生产力数据服务 生态系统类型分布数据服务 土壤类型质地养分数据服务 生态系统空间分布数据服务 增强型植被指数数据服务
多年平均气温空间分布数据服务 多年平均降水量空间分布数据服务 湿润指数数据服务 大于0℃积温空间分布数据服务 光合有效辐射分量数据服务 显热/潜热信息数据服务 波文比信息数据服务 地表净辐射通量数据服务 光合有效辐射数据服务 温度带分区数据服务 山区小气候因子精细数据服务
全国夜间灯光指数数据服务 全国GDP公里格网数据服务 全国建筑物总面积公里格网数据服务 全国人口密度数据服务 全国县级医院分布数据服务 人口调查空间分布数据服务 收入统计空间分布数据服务 矿山面积统计及分布数据服务 载畜量及空间分布数据服务 农作物种植面积统计数据服务 农田分类面积统计数据服务 农作物长势遥感监测数据服务 医疗资源统计数据服务 教育资源统计数据服务 行政辖区信息数据服务
Landsat 8 高分二号 高分一号 SPOT-6卫星影像 法国Pleiades高分卫星 资源三号卫星 风云3号 中巴资源卫星 NOAA/AVHRR MODIS Landsat TM 环境小卫星 Landsat MSS 天绘一号卫星影像





这一主题将介绍地统计研究的概化工作流以及主要步骤。正如什么是地统计中所述,地统计是用于分析和预测与空间现象或时空现象相关联的值的统计数据类。ArcGIS Geostatistical Analyst 提供一套工具,该工具允许构建使用空间(和时间)坐标的模型。这些模型可以应用于各种情况并通常用于生成未采样位置的预测,也可用于生成这些预测的不确定性的度量值。
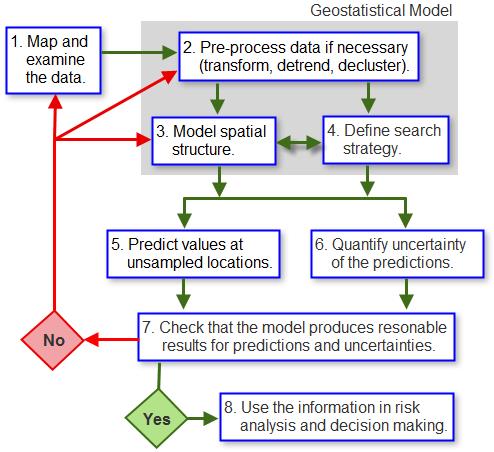
与几乎所有数据驱动研究相同,第一步是仔细检查数据。这通常从映射数据集、使用可使数据集可能显示的重要特征清晰可见的分类和颜色方案开始,例如,从北向南的值的显著增加(趋势);非特定排列方式中低值与高值的混合(可能是以某一并不显示空间相关性的比例获取数据的符号);或者是采样更加密集的区域(优先采样),该区域可能会使您决定在数据分析中使用去聚权重。第二步是构建地统计模型。根据研究的目的(即模型需要提供的信息类型)和被认为足够重要并需要纳入的数据集要素,这一过程需要几个步骤。在这一阶段,对数据集进行严密探索的期间收集到的信息和对现象的先验知识将决定模型的复杂程度和内插值的准确性,以及不确定性的度量值的准确性。在上图中,构建模型会涉及预处理数据以移除空间趋势,这些趋势是单独建模的,并在插值过程的最后一步中重新添加回去;变换数据以便其更加严格遵守高斯分布(一些方法和模型输出所需);以及对数据集去聚以补偿优先采样。由于检查数据集可以获得大量信息,因此纳入您可能拥有的对现象的认知很重要。建模器不能只依赖数据集来显示全部的重要要素;仍可以通过调整参数值将那些不显示的要素纳入到模型中,来反映预期结果。模型要尽可能地逼真,这一点很重要,以便内插值和相关的不确定性能够精确地表现实际现象。
除了预处理数据,可能还需要在数据集中为空间结构建模(空间相关性)。一些方法,如克里金法,需要使用半变异函数和协方差函数进行显式建模;而其他方法,如“反距离权重”,依赖于假设的空间结构度,这一空间结构度必须由建模器基于对现象的先验知识来提供。
模型的最后一个组成部分是搜索策略。其定义了用来为未采样位置生成值的数据点的数量。也可以定义其空间配置(相对于另一个位置以及未采样位置的位置)。这两个因素都会影响内插值及其相关的不确定性。对于许多方法来说,搜索椭圆是与椭圆分割成的扇形的数量以及从每个分区中获取的用来进行预测的点的数量一起定义的。
在完成模型定义之后,该模型可以与数据集结合使用来生成感兴趣区域内所有未采样位置的内插值。输出通常是显示正在建模的变量的值的地图。可以在这一步对异常值效果进行研究,因为其可能会更改模型的参数值,从而更改内插地图。根据插值方法,同一个模型也可以用来生成内插值的不确定性的度量值。不是所有的模型都具有这一功能,因此在开始时定义需要的不确定性度量值很重要。与所有建模尝试相同,模型的输出应该经过检查,即确保内插值和相关的不确定性的度量值是合理的并与预期相匹配。
构建并调整好模型并检查其输出之后,结果便可以用于风险分析和做出决策。


