全国高分辨率土地利用数据服务 土地利用数据服务 土地覆盖数据服务 坡度数据服务 土壤侵蚀数据服务 全国各省市DEM数据服务 耕地资源空间分布数据服务 草地资源空间分布数据服务 林地资源空间分布数据服务 水域资源空间分布数据服务 建设用地空间分布数据服务 地形、地貌、土壤数据服务 分坡度耕地数据服务 全国大宗农作物种植范围空间分布数据服务
多种卫星遥感数据反演植被覆盖度数据服务 地表反照率数据服务 比辐射率数据服务 地表温度数据服务 地表蒸腾与蒸散数据服务 归一化植被指数数据服务 叶面积指数数据服务 净初级生产力数据服务 净生态系统生产力数据服务 生态系统总初级生产力数据服务 生态系统类型分布数据服务 土壤类型质地养分数据服务 生态系统空间分布数据服务 增强型植被指数数据服务
多年平均气温空间分布数据服务 多年平均降水量空间分布数据服务 湿润指数数据服务 大于0℃积温空间分布数据服务 光合有效辐射分量数据服务 显热/潜热信息数据服务 波文比信息数据服务 地表净辐射通量数据服务 光合有效辐射数据服务 温度带分区数据服务 山区小气候因子精细数据服务
全国夜间灯光指数数据服务 全国GDP公里格网数据服务 全国建筑物总面积公里格网数据服务 全国人口密度数据服务 全国县级医院分布数据服务 人口调查空间分布数据服务 收入统计空间分布数据服务 矿山面积统计及分布数据服务 载畜量及空间分布数据服务 农作物种植面积统计数据服务 农田分类面积统计数据服务 农作物长势遥感监测数据服务 医疗资源统计数据服务 教育资源统计数据服务 行政辖区信息数据服务
Landsat 8 高分二号 高分一号 SPOT-6卫星影像 法国Pleiades高分卫星 资源三号卫星 风云3号 中巴资源卫星 NOAA/AVHRR MODIS Landsat TM 环境小卫星 Landsat MSS 天绘一号卫星影像





大家在用数据的时候,经常会碰到有重复的点。此文做了一个归总,提供给需要的人员。
思路:buffer \ merge \ explodemulti-part feature \ feature to point \ spatial join
说明:
重复点,在某个精度下很相近而可以认为是同一个点的点。
这里所谓的删除重复点,其实是通过点做缓冲,构成面;然后把构成的面合并起来,这样,重复点<< span="">或者近距离点>所形成的面的边界就会消融而形成一个面;然后打散,把不相邻的面分散成独立的要素;最后,生成这些面的质心点,即为所求。
这里有个重要的参数,就是缓冲距离,怎么定呢?可以参考数据精度;还可以用 Analysis tools\ proximity\ point distince算一下各点距离,找到认为不重复的点之间的最近距离,设置的缓冲距离应该比这个距离的一半要小。
这里说的Merge是编辑下的合并功能。Editor \Starting editing \全选buffer后的面层,选择Merge,合并到一个空图班上。这一步的作用是将相邻过近,以至于重复的点形成的面的边界消掉,融合一起。
在Editor下拉菜单选择AdvancedEditing,调出高级编辑工具条。
点击一下Merge后的面层,选择ExplodeMulti-part Feature。这一步的作用是将上一步生成的不相邻不重合而被融合在一起的多部件面给炸开,打散。
Arctoolbox\ data management tools\features \Features to points,生成打散后面的质心点。这样生成的点层,就达到了消除重复点的目的。
这一步,主要是把原始点层含的属性给带过来。可以点击图层,右键\Join and Relates \Join\Joindata from another layer based on spatial location,也可以从工具箱里analysistools\overlay \spatial Join,位置关系匹配方式,可以选择closest。
思路:先将点的坐标按 "x,y" 的格式写入一个字段,然后对这个字段进行重复项检查。两步都是使用field Calculate,输入VBA的计算字符即可。
新建字段[coordinate] ,类型设置为text,长度默认50,右击该字段,选择field Calculate,点advanced,填入一下表达式:
Dim Output As string
Dim pPoint As IPoint
Set pPoint = [Shape]
Output = pPoint.X& "," & pPoint.Y
新建字段[Dup],类型设置为long integer,右键选field Calculate,在advanced的表达式框中填入:
Static d As Object
Static i As Long
Dim iDup As Integer
Dim sField
'----------------------------------------
'这里填写需要检查的字段名
sField = [coordinate]
'----------------------------------------
If (i = 0) Then
Set d =CreateObject("Scripting.Dictionary")
End If
If(d.Exists(CStr(sField))) Then
iDup = 1
Else
d.Add CStr(sField), 1
iDup = 0
End If
i = i + 1
以下是原作者对上段代码的解释:
这段代码的思路,就是在第一行的时候,新建了一个"Scripting.Dictionary" 这算是一个容器(存放二维数组)。当VBA脚本在每一行执行的时候,都会把该条记录的[sField]字段值放到容器里比较一下。如果容器里没有,那么就添加进去,与此同时,把标识符 iDup赋值为 0;如果该条记录的[sField]字段值容器里已经存在了,那么,标识符iDup赋值为1。依次循环,一直到记录结束。
从思路里不难看出,不重复的,标记为0;重复值的第一条记录,会被标记为 0,剩下重复的都被标记为1.比如,该字段里有 4个A,A,A,A,第一个A,放到容器里一查,没有,那么把A放到容器里,该条记录标记为0,剩下的3个A,放到容器里查的时候,会发现已经存在了,会被标记为1。 从而达到查找和标记重复记录的目的。
if(d.Exists(Str(sField)) Then
iDup=1
这句话,就是说如果字段 [sField]的值在容器里已经存在了。
Else
d.Add Cstr(sField),1
iDup=0
这里,说的是不存在,就添加进去。
"Scripting.Dictionary" 这个容器存放的是二维数组,所以 d.add 后面跟着的2个参数。第一个参数是键,第二个参数是值。因为[sField] 已经不同了,所以后面那个值,可以是 1,也可以写2 或者其他。
在字段计算器里,[字段名]是取了该行的字段值。
这里可不可以删除在一定精度下不完全重复但是靠的很近的点呢?
可以在把坐标写入字段的时候控制一下,用format 函数规定好xy坐标输出的小数位数。
思路:如果数据是Geodatabase(mdb或gdb)格式,可考虑用SQL语句查询点x、y值相同的记录,并进行删除。
Data Management Tools\Features\Add XYCoordinates工具,为点数据计算x、y坐标值,结果会在属性表中生成POINT_X和POINT_Y两个字段。
在select by attributes窗口里输入:[OBJECTID]not in (select max(OBJECTID) from 图层名 group by point_x,point_y)。
选中的要素删掉即可。
此工具是ArcGIS10新推出的工具,可以删除重复的要素。Filed里勾上通过AddXY Coordinates工具计算的x、y坐标值,通过比较重复坐标值的要素,将其删除。用之前,可用Find Identical工具查找有无重复的点。
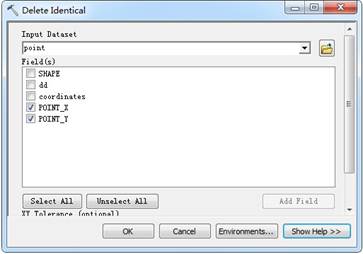
Delete Identical工具也可以选择用shape字段进行比较,并可以设置XY Tolerance来查找非常近的点。但是执行效果不佳,不知ArcGIS10.1有无改进。
可以把多个要素,通过指定的属性(属性值相同),溶解成一个要素。但dissolve会丢失没有指定的不同的属性。因此,该工具适合几何和属性完全重合的点数据。
这里,我们可以用Add XY Coordinates工具计算的x、y坐标值,然后用dissolve工具根据x、y两个字段进行溶解。


