全国高分辨率土地利用数据服务 土地利用数据服务 土地覆盖数据服务 坡度数据服务 土壤侵蚀数据服务 全国各省市DEM数据服务 耕地资源空间分布数据服务 草地资源空间分布数据服务 林地资源空间分布数据服务 水域资源空间分布数据服务 建设用地空间分布数据服务 地形、地貌、土壤数据服务 分坡度耕地数据服务 全国大宗农作物种植范围空间分布数据服务
多种卫星遥感数据反演植被覆盖度数据服务 地表反照率数据服务 比辐射率数据服务 地表温度数据服务 地表蒸腾与蒸散数据服务 归一化植被指数数据服务 叶面积指数数据服务 净初级生产力数据服务 净生态系统生产力数据服务 生态系统总初级生产力数据服务 生态系统类型分布数据服务 土壤类型质地养分数据服务 生态系统空间分布数据服务 增强型植被指数数据服务
多年平均气温空间分布数据服务 多年平均降水量空间分布数据服务 湿润指数数据服务 大于0℃积温空间分布数据服务 光合有效辐射分量数据服务 显热/潜热信息数据服务 波文比信息数据服务 地表净辐射通量数据服务 光合有效辐射数据服务 温度带分区数据服务 山区小气候因子精细数据服务
全国夜间灯光指数数据服务 全国GDP公里格网数据服务 全国建筑物总面积公里格网数据服务 全国人口密度数据服务 全国县级医院分布数据服务 人口调查空间分布数据服务 收入统计空间分布数据服务 矿山面积统计及分布数据服务 载畜量及空间分布数据服务 农作物种植面积统计数据服务 农田分类面积统计数据服务 农作物长势遥感监测数据服务 医疗资源统计数据服务 教育资源统计数据服务 行政辖区信息数据服务
Landsat 8 高分二号 高分一号 SPOT-6卫星影像 法国Pleiades高分卫星 资源三号卫星 风云3号 中巴资源卫星 NOAA/AVHRR MODIS Landsat TM 环境小卫星 Landsat MSS 天绘一号卫星影像





这个问题其实和分区统计管线长度,或者分省统计铁路长度其实是一样的,那么在ArcGIS中,我们要如何实现呢?
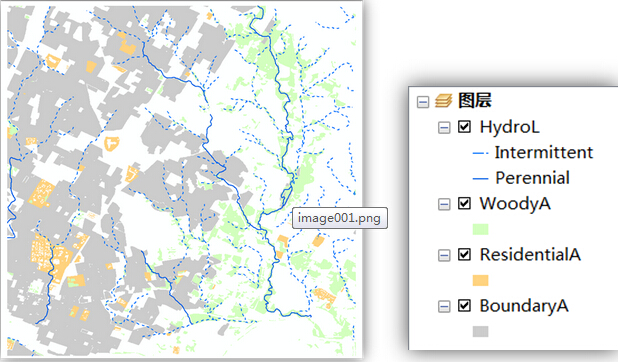
图1 现有数据和图例
在本例中,区域之间的重合是被允许的,如果计算的是各行政区的河流(管线)总长度,即各区域之间不允许重合,则在处理之前,需要先进行拓扑修正。
打开ArcCatalog,在要素数据集上右键新建拓扑,按照系统向导一步一步设置:
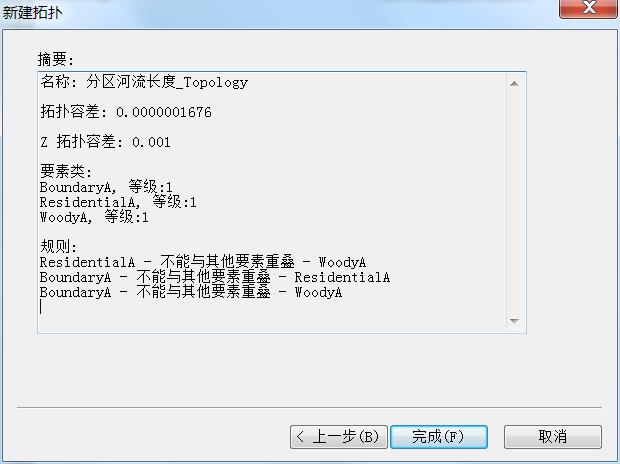
名称:分区河流长度_Topology;
拓扑容差:保持默认;
参与到拓扑中的要素类:三个面要素;
等级:保持默认;
拓扑规则:BoundaryA不能与其他要素重叠ResidentialA,BoundaryA不能与其他要素重叠WoodyA,ResidentialA不能与其他要素重叠WoodyA。
最终摘要如图。
完成后在弹出的是否立即验证的对话框中选择否。
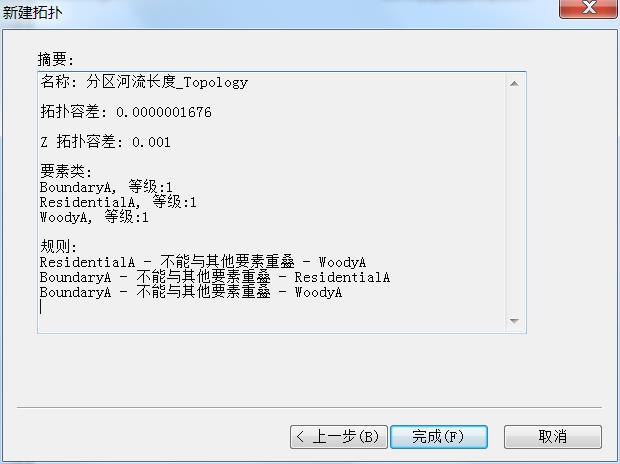
图2 新建拓扑摘要
打开ArcMap,将新建的拓扑以及对应的数据加载进来。
开启编辑,调用拓扑工具条,将视图缩放到所有图层,单击验证当前范围中的拓扑,然后打开错误检查器,对表格中的拓扑错误逐一排查修正。

图3 拓扑工具条
在每一条错误上右键会显示系统提供的错误修改方法,对于面和面重叠的拓扑错误一般选择系统建议的合并方法即可,单击合并后会出现合并选择对话框,选择需要合并的要素,单击确定修改。
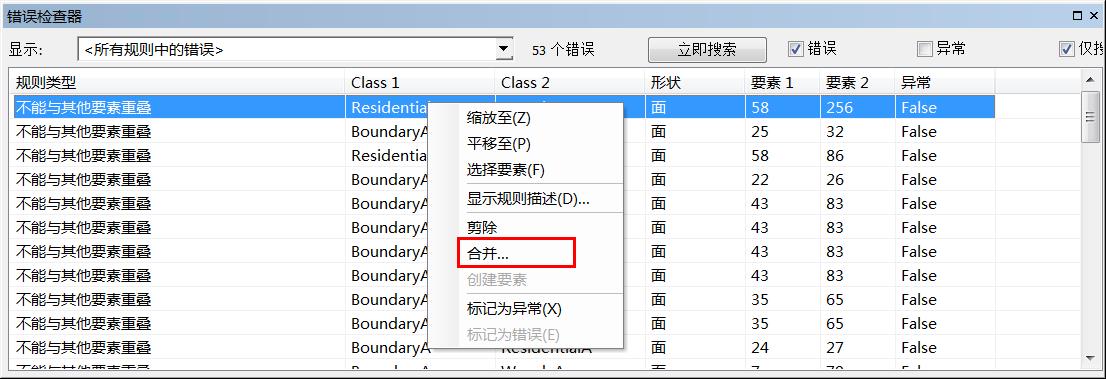
图4 错误检查器
然后对处理完成的数据,我们需要做的就是让每条河流都有一个字段值可以分辨出它流经的区域,我们通过标识(Identity)工具实现。
打开toolbox, 依次选择分析工具(Analysis Tools) > 叠加分析(Overlay) > 标识(Identity),相关参数设置如下:
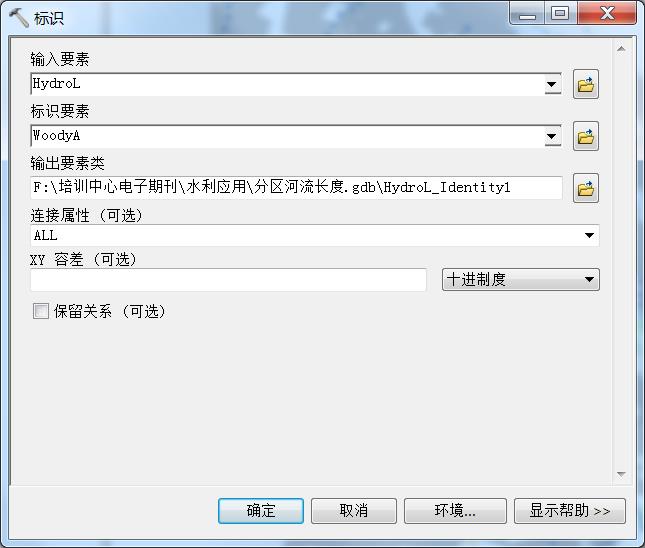
图5 标识(Identity)工具对话框
通过以上操作,将河流按woody的边界断开,并生成新的带有woody标识的河流图层,其中每段河流都包含了woody图层的属性。
同理,我们需要将residential和boundary图层也标识到河流上。
再次运行标识(Identity)工具,输入要素:HydroL_Identity1;标识要素:ResidentialA;输出要素:HydroL_Identity2;连接属性:ALL。
第三次运行标识(Identity)工具,输入要素:HydroL_Identity2;标识要素:BoundaryA;输出要素:HydroL_Identity3;连接属性:ALL。
接下来需要计算新HydroL图层每段河流的长度。
首先需要新建一个字段用于存储河流长度。在内容列表(TOC)中右键HydroL_Identity3图层,单击打开属性表,表选项(Options) > 添加字段(Addfield),字段名为“length”,类型为“双精度”。
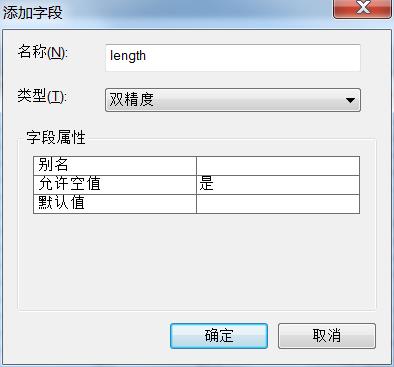
图6 新建字段对话框
右键length字段计算几何(CalculateGeometry),打开计算几何对话框,设置如下,计算该坐标投影下每段河流的长度
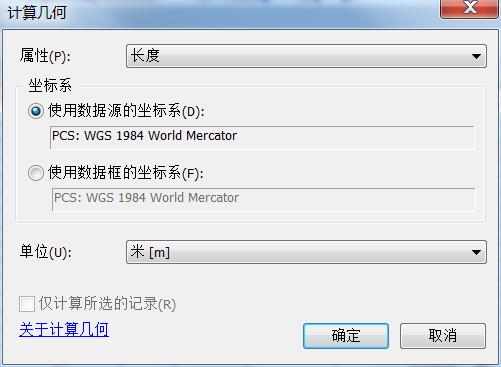
图7 计算几何对话框
注意:
①计算河流长度要素类必须具有投影坐标系统;
②如果要素类存储在Geodatabase中,则可以直接使用Shape_Length字段中的值。
下面我们需要根据不同的区域进行长度统计。
打开Toolbox,分析工具(AnalysisTools) > 统计分析(Statistics) > 汇总统计数据(SummaryStatistics),参数设置如下:
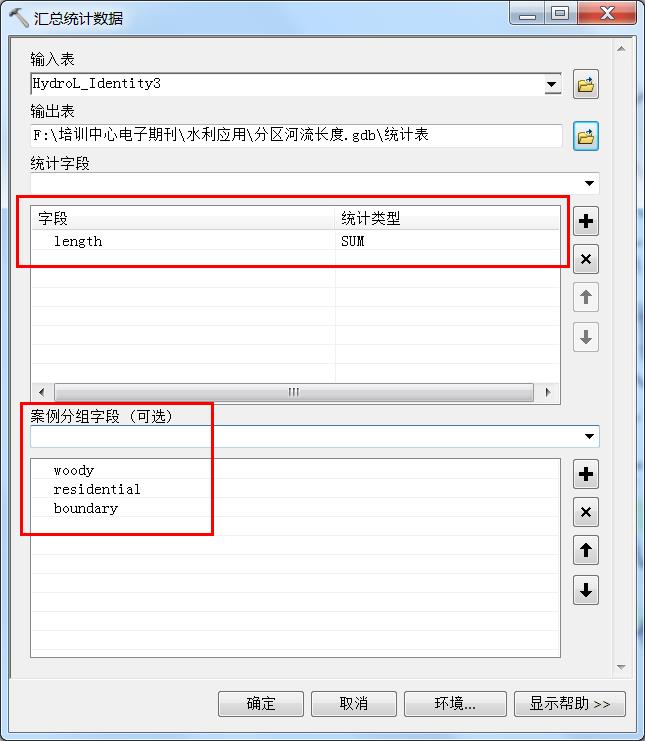
图8 汇总统计数据对话框
统计字段:如果是shapefile格式,选择第二步新建的字段;如果是Geodatabase格式,直接选择Shape_Length字段。
统计类型:选择SUM;
案例分组字段:选择具有唯一标识的字段,例如,在本案例中,woody字段中存储的值为1,标识这条河流位于woody区域内。
最终会生成一张dbf表格,内容如下:
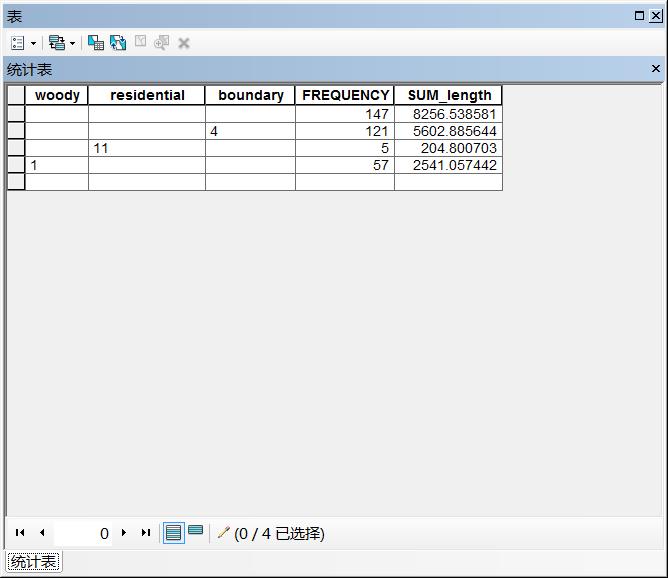
图9 最终结果表
SUM_length字段可以清楚地看到每个区域的河流总长度,另外还会发现有些河流没有流经任何区域。
如果没有进行第一步,即允许区域之间重合,那么最终结果还会显示出流经多个区域的河流的长度,如图10所示。
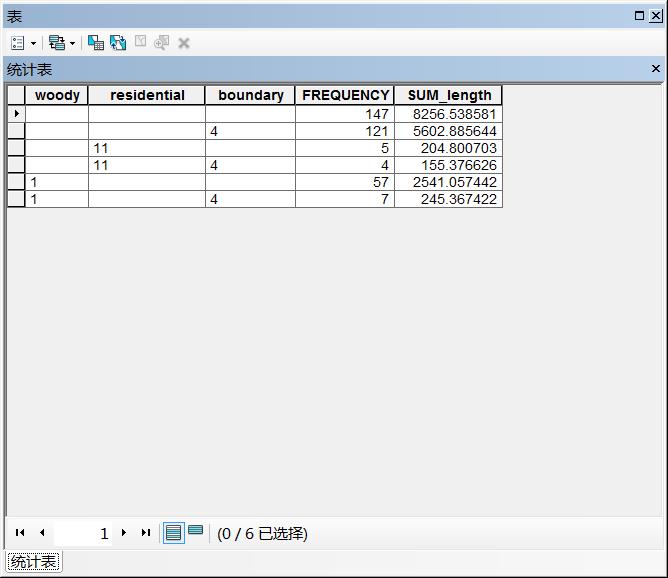
图10 未经拓扑修正的结果图


