
全国高分辨率土地利用数据服务 土地利用数据服务 土地覆盖数据服务 坡度数据服务 土壤侵蚀数据服务 全国各省市DEM数据服务 耕地资源空间分布数据服务 草地资源空间分布数据服务 林地资源空间分布数据服务 水域资源空间分布数据服务 建设用地空间分布数据服务 地形、地貌、土壤数据服务 分坡度耕地数据服务 全国大宗农作物种植范围空间分布数据服务
多种卫星遥感数据反演植被覆盖度数据服务 地表反照率数据服务 比辐射率数据服务 地表温度数据服务 地表蒸腾与蒸散数据服务 归一化植被指数数据服务 叶面积指数数据服务 净初级生产力数据服务 净生态系统生产力数据服务 生态系统总初级生产力数据服务 生态系统类型分布数据服务 土壤类型质地养分数据服务 生态系统空间分布数据服务 增强型植被指数数据服务
多年平均气温空间分布数据服务 多年平均降水量空间分布数据服务 湿润指数数据服务 大于0℃积温空间分布数据服务 光合有效辐射分量数据服务 显热/潜热信息数据服务 波文比信息数据服务 地表净辐射通量数据服务 光合有效辐射数据服务 温度带分区数据服务 山区小气候因子精细数据服务
全国夜间灯光指数数据服务 全国GDP公里格网数据服务 全国建筑物总面积公里格网数据服务 全国人口密度数据服务 全国县级医院分布数据服务 人口调查空间分布数据服务 收入统计空间分布数据服务 矿山面积统计及分布数据服务 载畜量及空间分布数据服务 农作物种植面积统计数据服务 农田分类面积统计数据服务 农作物长势遥感监测数据服务 医疗资源统计数据服务 教育资源统计数据服务 行政辖区信息数据服务
Landsat 8 高分二号 高分一号 SPOT-6卫星影像 法国Pleiades高分卫星 资源三号卫星 风云3号 中巴资源卫星 NOAA/AVHRR MODIS Landsat TM 环境小卫星 Landsat MSS 天绘一号卫星影像





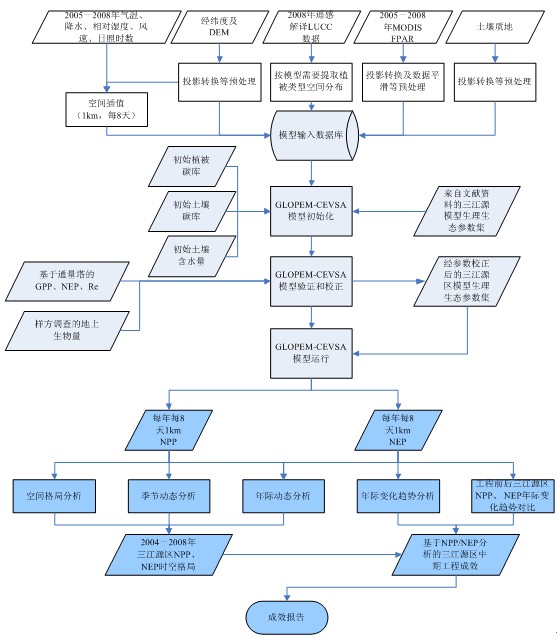
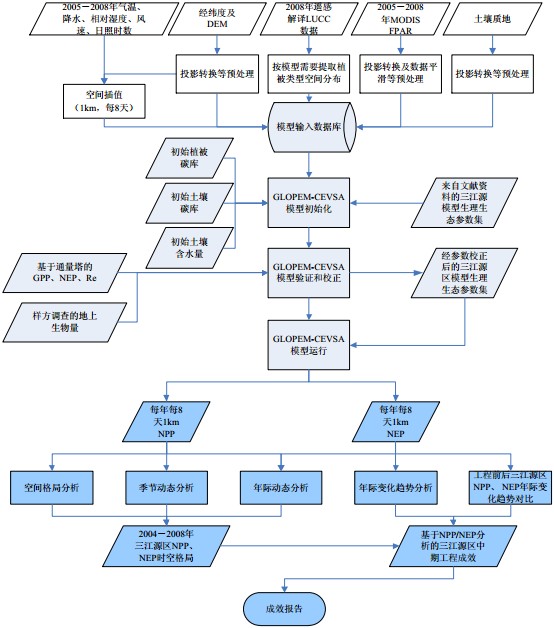
三江源区的 NPP/NEP 获取与分析的技术路线如图 1 所示,主要包括三部分内容:(1)数据准备,包括气象台站数据、项目组解译的 2008 年 LUCC 数据、土壤数据等;(2)模型运行,包括模型初始化,模型验证和校正及模型的最终运行获得结果;(3)模拟结果分析,并给出结果报告。
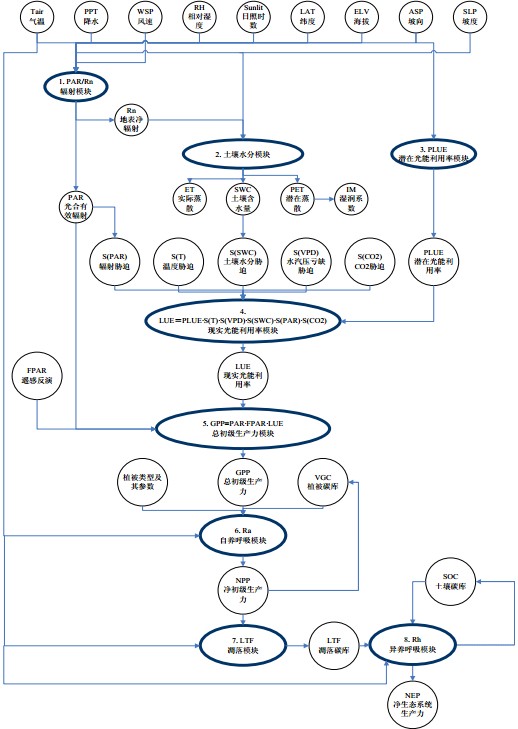
本方案采用生态系统过程-遥感模型(GLOPEM-CEVSA),在对其进一步验证的基础上,模拟评估期间植被净初级生产力。 GLOPEM-CEVSA 模型的基本框架为图 1 所示,它依据碳循环过程,模拟光能利用率,以卫星遥感反演的 FPAR 模拟植被吸收的光合有效辐射(APAR),获得植被总初级生产力(GPP);以植被生物量和气温及不同植被群落的维持性呼吸系数及温度关系模拟植被维持性呼吸(Rm)和生长性呼吸(Rg),获得植被净第一性生产力(NPP);植被通过自养呼吸释放一部分光合作用固定的碳到大气中,其余的碳按分配模式分配到根、茎和叶中储存或凋落,凋落物进入土壤后,与土壤中原有的有机质在微生物等的作用下进行异养呼吸(Rh),将生态系统固定的一部分碳释放到大气中,最后固定在植被中的这部分碳即为净生态系统生产力。
该模型包括 8 个模块:辐射模块、土壤水分模块、潜在光能利用率模块、现实光能利用率模块、总初级生产力模块、自养呼吸模块、凋落物分解模块及土壤异养呼吸模块。
模型输入数据包括气象台站插值数据气温、降水、空气湿度、风速、相对湿度,及通过卫星遥感反演的 FPAR。
气象数据(温度、降水量、风速、日照时数和相对湿度)以 2004-2008 年每日的三江源地区气象台站观测数据,以及来自全国气象气象站点的三江源周边地区气象台站数据进行空间内插得到,空间分辨率为 1km 网格,时间分辨率为 8d。所使用的插值方法是由澳大利亚国立大学基于利用光滑薄板样条法开发的插值软件 ANUSPLIN。在内插过程中主要考虑经纬度和海拔高度对各气候要素的影响,并利用分辨率为 1km 网格的数字高程数据按线性关系对样条函数得到的表面进行拟合,得到最后的内插结果。
基于卫星遥感参数反演的 FPAR 采用经传感器间差异校正的 1km 分辨率的 MODIS/FPAR 数据产品(MOD15A2 产品),该产品是以美国地球观测系统(EOS)开发的辐射传输算法,利用 MODIS 红波段和近红外波段反演。
该气候区划用于陆表太阳总辐射计算,来自全国气候区划图。
本方案中采用的植被覆盖类型图是基于 30m 分辨率 Landsat 遥感数据的三江源地区 2004-2008年土地覆盖图。植被类型用于确定植被自养呼吸参数、植被分配及周转时间。
采用的土壤质地数据来自全国土壤质地数据。该数据选取了第二次土壤普查共 516 个剖面点,计算了土壤的粒级结构。然后,根据 1:400 万土壤类型图(中国科学院南京土壤研究所,1978;中国科学院地理研究所资源与环境信息系统国家重点实验室, 1996)做空间插值,对每一个一级类别所覆盖的土壤剖面点计算粒级机构的平均值,作为此土壤类型的粒级构成。
土壤质地数据用于土壤水分参数的计算,土壤水势 ψ 和相对干燥率 RDR 的计算,以及土壤异养呼吸模拟。
高程数据将采用三江源区 1: 10 万地形图和 1: 5 万地形图,经地形图全要素数字化后生成的 DEM数据。
利用遥感数据处理系统中的地形分析模块,以该 DEM 数据分别生成坡度和坡向数据,用于模型中地表太阳总辐射和净辐射计算。
用于模型初始化的植被碳库数据是利用全国森林资源统计(1989-1993)提供的林分各优势树种面积蓄积统计数据,及根据文献资料的生物量(B)与蓄积量(V)关系式,计算出各优势树种的总生物量,及各类森林植被类型的平均生物量。同时也参考了国内多位学者对全国森林、农田、草地、荒漠等生物量的研究结果,得出了应用于本方案中模型初始化的植被碳库数据。
土壤碳库数据是根据中国较为完善和精确的第二次土壤普查(1979-1994)统计资料,在地理信息系统的支持下,建立初步的土壤剖面数据库,然后利用中国资源环境数据库 1:400 万中国土壤类型分布图,将数据空间化得到全国土壤碳库空间分布数据。 在本方案中,从全国土壤碳库数据切割出青海地区数据,以初始化模型。
土壤水分平衡模拟中,首先根据土壤质地计算土壤田间持水量,将田间持水量作为土壤初始含水量,以 1988~2004 年气象资料及遥感的 FPAR 运行模型,将得到的 2004 年最后时相(12 月底)的模拟的土壤含水量和积雪值作为 1988 年第一时相(1 月初)的初始值,如此反复多次迭代模拟,直至水分平衡状态。
在模型模拟中,首先应用 1988~2004 年平均气温和降水资料,及期间遥感观测的 FPAR 运行模型,得到每 8 天 NPP,然后计算该时期年平均 NPP 及每 8 天日平均 NPP,另外,加之用于初始化模型的植被碳库数据,迭代运行模型至生态系统平衡态,即各个状态变量如植被和土壤碳贮量等的年际变化小于 0.1%,并且 NPP、LT(Litter Productivity, 凋落物量)、和 HR 相等(即 NEP 为零),得到平衡态植被碳库和土壤碳库,然后用 2004~2008 年每 8 天气象资料,及遥感反演的 FPAR 进行动态模拟。
模型中其它参数,如自养呼吸、异养呼吸等计算中涉及一些与植被类型相关的参数,针对青藏高原植被特点,将通过文献资料,结合当地碳通量观测塔数据,进行参数校正,使模型进一步适合三江源地区。利用三江源区通量观测并计算获得的生态系统总生产力(GPP) 、生态系统总呼吸(Re)和生态系统碳交换量(NEE) ,以及生态系统水分通量(ET)数据,对模型进行验证和参数校正。
用 2004~2008 年每 8 天气象资料,及遥感反演的 FPAR 进行动态模拟,获得 NPP、NEP,进行结果分析。主要用于分析:
(1) 2004-2008 年三江源区 NPP/NEP 时空格局
(2) 2004-2008 年三江源区主要生态系统 NPP/NEP 变化趋势
(3) 2004-2008 年三江源区主要流域 NPP/NEP 变化趋势
(4) 与 1990-2004 年生态工程建设之前相对比下的 2004-2008 年三江源地区生态系统NPP/NEP 变化趋势



