全国高分辨率土地利用数据服务 土地利用数据服务 土地覆盖数据服务 坡度数据服务 土壤侵蚀数据服务 全国各省市DEM数据服务 耕地资源空间分布数据服务 草地资源空间分布数据服务 林地资源空间分布数据服务 水域资源空间分布数据服务 建设用地空间分布数据服务 地形、地貌、土壤数据服务 分坡度耕地数据服务 全国大宗农作物种植范围空间分布数据服务
多种卫星遥感数据反演植被覆盖度数据服务 地表反照率数据服务 比辐射率数据服务 地表温度数据服务 地表蒸腾与蒸散数据服务 归一化植被指数数据服务 叶面积指数数据服务 净初级生产力数据服务 净生态系统生产力数据服务 生态系统总初级生产力数据服务 生态系统类型分布数据服务 土壤类型质地养分数据服务 生态系统空间分布数据服务 增强型植被指数数据服务
多年平均气温空间分布数据服务 多年平均降水量空间分布数据服务 湿润指数数据服务 大于0℃积温空间分布数据服务 光合有效辐射分量数据服务 显热/潜热信息数据服务 波文比信息数据服务 地表净辐射通量数据服务 光合有效辐射数据服务 温度带分区数据服务 山区小气候因子精细数据服务
全国夜间灯光指数数据服务 全国GDP公里格网数据服务 全国建筑物总面积公里格网数据服务 全国人口密度数据服务 全国县级医院分布数据服务 人口调查空间分布数据服务 收入统计空间分布数据服务 矿山面积统计及分布数据服务 载畜量及空间分布数据服务 农作物种植面积统计数据服务 农田分类面积统计数据服务 农作物长势遥感监测数据服务 医疗资源统计数据服务 教育资源统计数据服务 行政辖区信息数据服务
Landsat 8 高分二号 高分一号 SPOT-6卫星影像 法国Pleiades高分卫星 资源三号卫星 风云3号 中巴资源卫星 NOAA/AVHRR MODIS Landsat TM 环境小卫星 Landsat MSS 天绘一号卫星影像





下一步是根据组成经验半变异函数的点拟合模型。半变异函数建模是空间描述和空间预测之间的关键步骤。克里金法的主要应用是预测未采样位置处的属性值。经验半变异函数可提供有关数据集的空间自相关的信息。但是,不提供所有可能的方向和距离的信息。因此,为确保克里金法预测的克里金法方差为正值,根据经验半变异函数拟合模型(即,连续函数或曲线)是很有必要的。该操作理论上类似于回归分析,在此回归分析中将根据数据点拟合连续线或曲线。
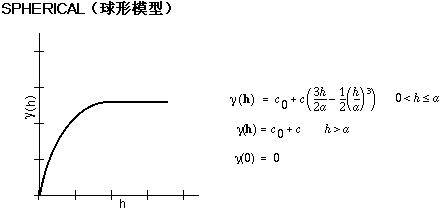
要根据经验半变异函数拟合模型,则选择用作模型的函数(例如,开始时上升并在距离变大而超过某一范围后呈现水平状态的球面类型)(请参阅下面的球面模型示例)。经验半变异函数上的点与模型有一些偏差;一些点在模型曲线上方,一些点在模型曲线下方。但是,如果添加一个相应的距离,每个点都会在线上方,或者如果添加另一个相应的距离,每个点都会在线下方,这两个距离值应该是相似的。有多种半变异函数模型可供选择。
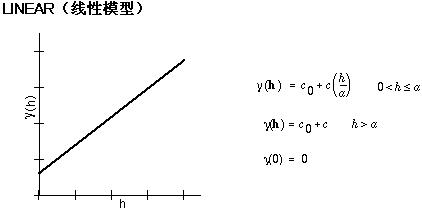
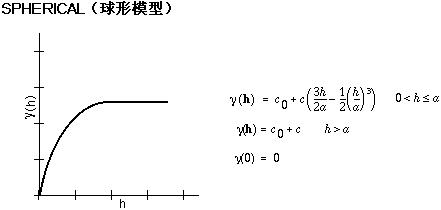
克里金法工具提供了以下函数,可以从中选择用于经验半变异函数建模的函数:
所选模型会影响未知值的预测,尤其是当接近原点的曲线形状明显不同时。接近原点处的曲线越陡,最接近的相邻元素对预测的影响就越大。这样,输出曲面将更不平滑。每个模型都用于更准确地拟合不同种类的现象。
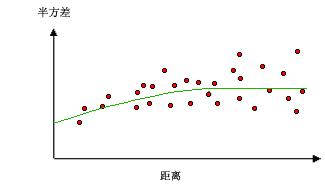
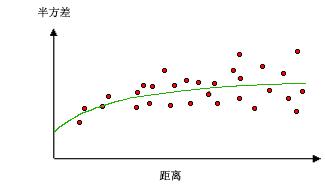
下图显示了两个常用模型并确定了函数的不同之处:
该模型显示了空间自相关逐渐减小(等同于半方差的增加)到超出某个距离后自相关为零的过程。球面模型是最常用的模型之一。
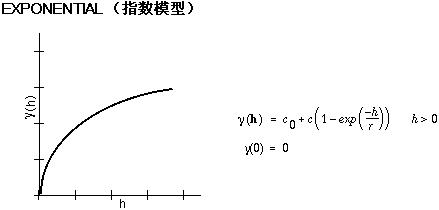
该模型在空间自相关随距离的增加呈指数减小时应用。在这里,自相关仅会在无穷远处完全消失。指数模型也是常用模型。要选择使用哪个模型基于数据的空间自相关和数据现象的先验知识。
正如前文所述,半变异函数显示了测量样本点的空间自相关。由于地理的基本原则(距离越近的事物就越相似),通常,接近的测量点的差值平方比距离很远的测量点的差值平方小。各位置对经调整后进行绘制,然后模型根据这些位置进行拟合。通常使用变程、基台和块金描述这些模型。
查看半变异函数的模型时,您将注意到模型会在特定距离处呈现水平状态。模型首次呈现水平状态的距离称为变程。比该变程近的距离分隔的样本位置与空间自相关,而距离远于该变程的样本位置不与空间自相关。
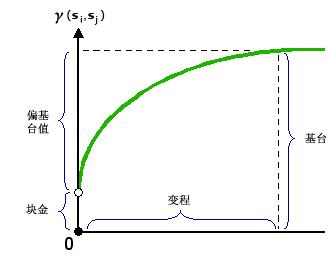
半变异函数模型在变程处所获得的值(y 轴上的值)称为基台。偏基台等于基台减去块金。块金会在以下部分进行描述。
从理论上讲,在零间距(例如,步长 = 0)处,半变异函数值是 0。但是,在无限小的间距处,半变异函数通常显示块金效应,即值大于 0。如果半变异函数模型在 y 轴上的截距为 2,则块金为 2。
块金效应可以归因于测量误差或小于采样间隔距离处的空间变化源(或两者)。由于测量设备中存在固有误差,因此会出现测量误差。自然现象可随着比例范围变化而产生空间变化。小于样本距离的微刻度变化将表现为块金效应的一部分。收集数据之前,能够理解所关注的空间变化比例非常重要。
找出数据中的相关性或自相关性并完成首次数据应用后(即,使用数据中的空间信息计算距离和执行空间自相关建模),您可以使用拟合的模型进行预测。此后,将撇开经验半变异函数。
现在即可使用这些数据进行预测。与反距离权重法插值类似,克里金法通过周围的测量值生成权重来预测未测量位置。与反距离权重法插值相同,与未测量位置距离最近的测量值受到的影响最大。但是,周围测量点的克里金法权重比反距离权重法权重更复杂一些。反距离权重法使用基于距离的简单算法,但是克里金法的权重取自通过查看数据的空间特性开发的半变异函数。要创建某现象的连续表面,将对研究区域(该区域基于半变异函数和附近测量值的空间排列)中的每个位置或单元中心进行预测。
有两种克里金方法:普通克里金法和泛克里金法。
普通克里金法是最普通和广泛使用的克里金方法,是一种默认方法。该方法假定恒定且未知的平均值。如果不能拿出科学根据进行反驳,这就是一个合理假设。
泛克里金法假定数据中存在覆盖趋势,例如,可以通过确定性函数(多项式)建模的盛行风。该多项式会从原始测量点扣除,自相关会通过随机误差建模。通过随机误差拟合模型后,在进行预测前,多项式会被添加回预测以得出有意义的结果。应该仅在您了解数据中存在某种趋势并能够提供科学判断描述泛克里金法时,才可使用该方法。
克里金法是一个复杂过程,需要的有关空间统计的知识比本主题中介绍的还要多。使用克里金法之前,您应对其基础知识全面理解并对使用该技术进行建模的数据的适宜性进行评估。如果没有充分理解该过程,强烈建议您查看本主题结尾列出的一些参考书目。
克里金法基于地区化的变量理论,该理论假定 z 值表示的现象中的空间变化在整个表面就统计意义而言是一致的(例如,在表面的所有位置处均可观察到相同的变化图案)。该空间一致性假设对于地区化的变量理论是十分重要的。
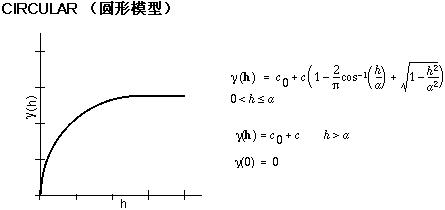
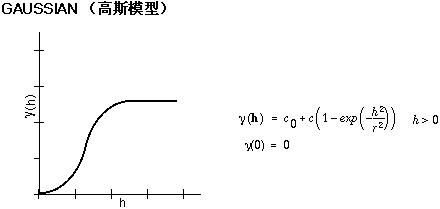
下面是用于描述半方差的数学模型的常用形状和方程。